![[CS] 캐시 메모리의 총정리 (Direct Mapping Cache를 중점으로)](https://img1.daumcdn.net/thumb/R750x0/?scode=mtistory2&fname=https%3A%2F%2Fblog.kakaocdn.net%2Fdn%2Fwwhmt%2FbtsGCozAY5H%2F7ikm8g4VknlRzhXDFCeJjk%2Fimg.jpg)

🖥️ 들어가며
자꾸 헷갈렸던 캐시 메모리의 총정리를 해보려고 한다. 왜 이리 헷갈리는지 드디어 가닥을 잡은 것 같아 포스팅으로 이 기억을 남기려고 한다.
🔍 캐시(Cache)란?
프로세스는 트랜지스터의 등장 이후 굉장히 빠른 속도로 발전한 반면, 메모리의 발전 속도는 프로세서에 비해 굉장히 더디게 발전했다. 이런 속도 간격을 메꾸기 위해 캐시(Cache) 가 나오게 되었다.
캐시는 CPU 안에 들어가는 매우 빠른 메모리다. 자주 사용하는 데이터들은 미리 캐시에 넣어둔 후, 프로세서가 메인 메모리 대신 캐시에서 데이터를 가져오도록 해 처리 속도를 높이는 것이 목적이다.
💡 메모리 구조

그림에서 보는 바와 같이, 속도는 위로 올라갈수록 빨라지고 용량은 위로 올라갈수록 적어진다. 그리고 가장 중요하게 알아 둬야 할 것은 인접한 두 계층 사이에서만 데이터 전송이 일어난다는 것이다.
그럼 이러한 질문이 나올 수 있다.
왜 레지스터랑 캐시 메모리를 많이 만들지 않나요?
여러 이유가 있지만, 우선 가장 큰 이유는 비용이다. 또한 레지스터나 캐시 메모리는 작기 때문에 빠르다는 특성을 가지고 있다. 작아야 전기 신호가 빠르게 이동하고, 데이터에 더 빠르게 접근할 수 있기 때문이다.
🔍 캐시 메모리 ‘자주 사용하는 데이터’ 특성
자주 사용하는 데이터 의 기준은 지역성을 따른다.
📌 시간적 지역성
한번 참조된 항목은 곧바로 다시 참조되는 경향을 말한다.
가장 간단한 예는 반복문이다.
for (int i = 0; i < 10; i++) {
arr[i] = i;
}여기서 변수 i는 곧바로 계속 참조되는 경향이 있다.
📌 공간적 지역성
참조된 어떤 항목 근처의 다른 항목들이 곧바로 다시 참조되는 경향을 말한다.
이것도 반복문을 보면 쉽게 알 수 있다.
for (int i = 0; i < 10; i++) {
arr[i] = i;
}arr 의 요소는 붙어있으므로 근처 요소들이 곧바로 다시 참조된다.

출처 : https://parksb.github.io/article/29.html
🔍 캐시의 구조
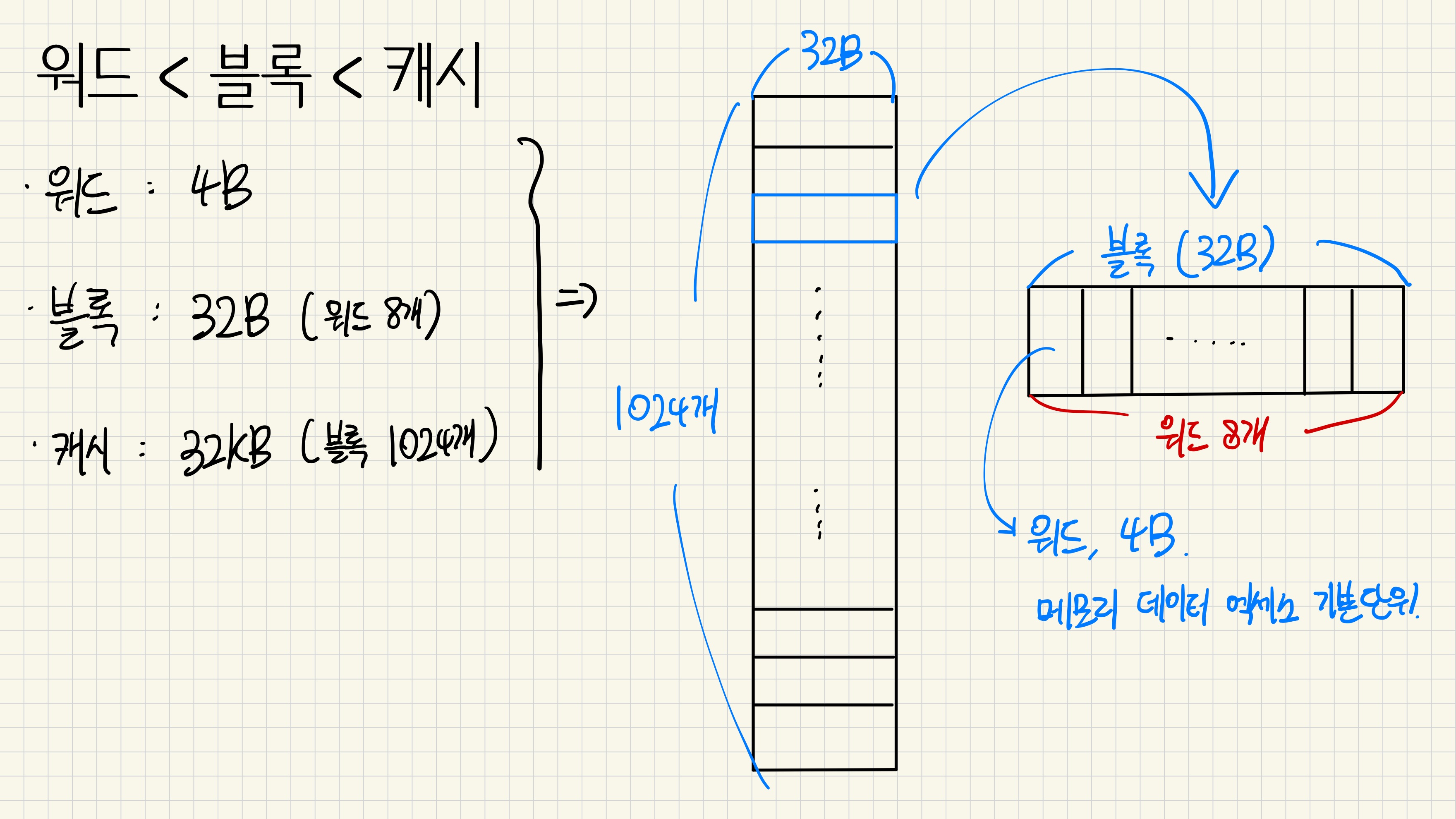
먼저 캐시를 알기 위해서는 워드 와 블록 을 알아야 한다.
또한 대전제로, 메모리는 1byte 단위로 취급된다는 것도 알아야 한다. bit 단위가 아니다!
📌 워드 (Word)
메모리에서 데이터를 액세스하는 기본 단위이다. 보통 32bit 운영체제에서는 32bit , 즉 4B 가 데이터 엑세스 기본 단위이다.
📌 블록 (Block)
데이터의 기본 저장 단위이다. 각 블록은 특정 크기(예 : 32B)의 데이터를 저장하며, 여러 개의 워드를 포함한다.
즉 블록이 32B의 데이터를 저장하면 32bit 운영체제에서 워드의 크기는 4B 이니 4개의 워드가 포함된다.
📌 캐시 (Cache)
여러 개의 블록들의 집합이다. 즉 캐시의 크기는 블록이 몇 개 있는지에 따라 결정된다.
예를 들어, 각 블록이 32B를 저장할 수 있고 총 1024개의 블록이 있다면, 캐시의 전체 크기는 32B × 1024 블록 = 32,768B (32KB) 가 된다.
그림으로 나타내면 다음과 같다.
🔍 캐시의 작동 방식
이제 캐시가 어떻게 작동하는지 알아야 한다.
CPU에서 요청한 데이터가 캐시에 존재할 때 캐시 히트 (Hit) 라고 한다. 캐시에 존재하지 않으면 미스 (Miss) 났다고 하며, 하위 메모리에서 다시 값을 가져와야 한다.
그렇다면 CPU에서 어떤 메모리에 존재하는 데이터를 가져오기 위해 주소가 주어졌을 때, 어떻게 이 데이터가 캐시에 존재하는지, 즉 Hit 날 것인지 알 수 있을까?
여러 방법이 있지만, 일단 여기서는 Direct Mapping Cache 에 대해 설명하려고 한다.
📌 인덱싱
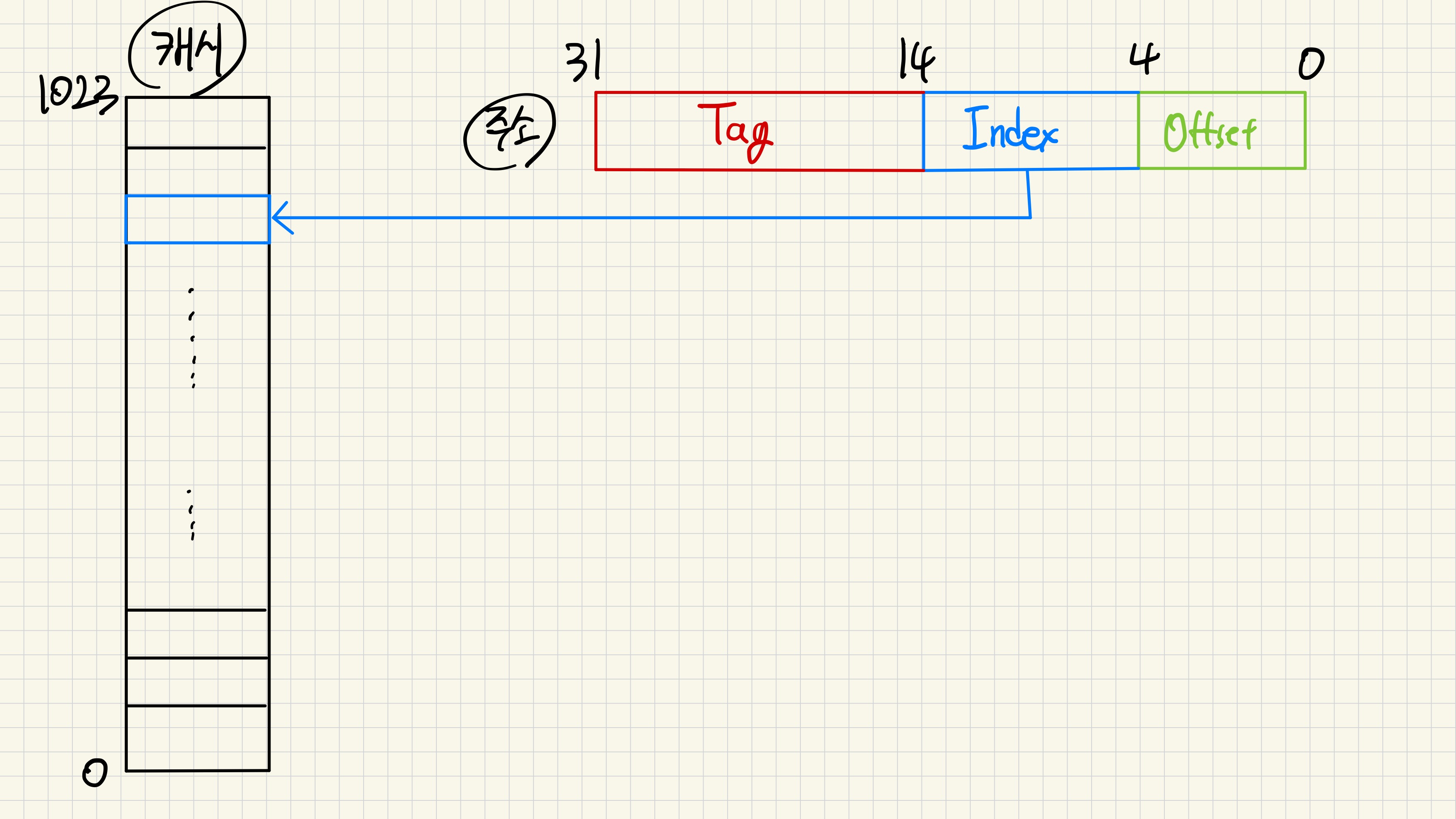
캐시는 당연하게도 메모리보다는 작으므로 32bit 전체를 가지고 바로 캐시로 접근할 수는 없다. 그러므로 Indexing 작업을 통해 접근한다.
위에서 가정했던 바와 같이 캐시 블록의 수가 1024개, 블록 사이즈가 32바이트라고 가정하자.
→ $1024=2^{10}$ 이므로 캐시 블록의 개수를 나타나는 데 10bit 가 필요하다.
→ 받은 전체 주소에서 하위 5bit 를 Offset 으로 지정하고, 이후 10bit 를 Index 로 사용해 캐시 블록에 접근한다.
그러나 이렇게만 사용한다면 캐시에 데이터가 존재한다면 이 데이터가 요청한 데이터가 맞는지 알기 힘들다. 중복되는 데이터가 굉장히 많기 때문이다.
그렇기에 이런 충돌을 줄이기 위해 Tag 와 Vaild 를 사용한다.
📌 태그 매칭과 Vaild

- 주소의
Index를 찾아 캐시로 들어간다. Vaild값이 0이라면 데이터가 없던 것, 1이라면 데이터가 있던 것이다. 0이라면 하위 메모리 계층에서 데이터를 갖고 와야 한다.Tag를 비교해 일치하면 원하든 데이터인 것이므로Hit처리하고Data를 반환한다.
📌 Offset의 사용처
오프셋은 데이터의 정확한 위치를 찾기 위해 사용한다.
캐시에는 여러 블록이 있고, 물론 주소가 하나의 블록을 가리키지만 블록에도 여러 워드가 존재한다.
만약 블록이 32B라 가정하자. $32=2^5$ 이므로 블록 내부 데이터를 가리킬 때 5bit 가 필요하다.
즉, 더 빠르게 데이터에 접근하기 위한 값이라 할 수 있다.
워드를 다시 생각해보자. 블록이 32B 라면 워드는 4B 이기 때문에 블록에 8개의 워드가 들어간다.
→ $8=2^3$ 이므로 워드의 위치를 나타내는 데에 3bit 가 필요하다.
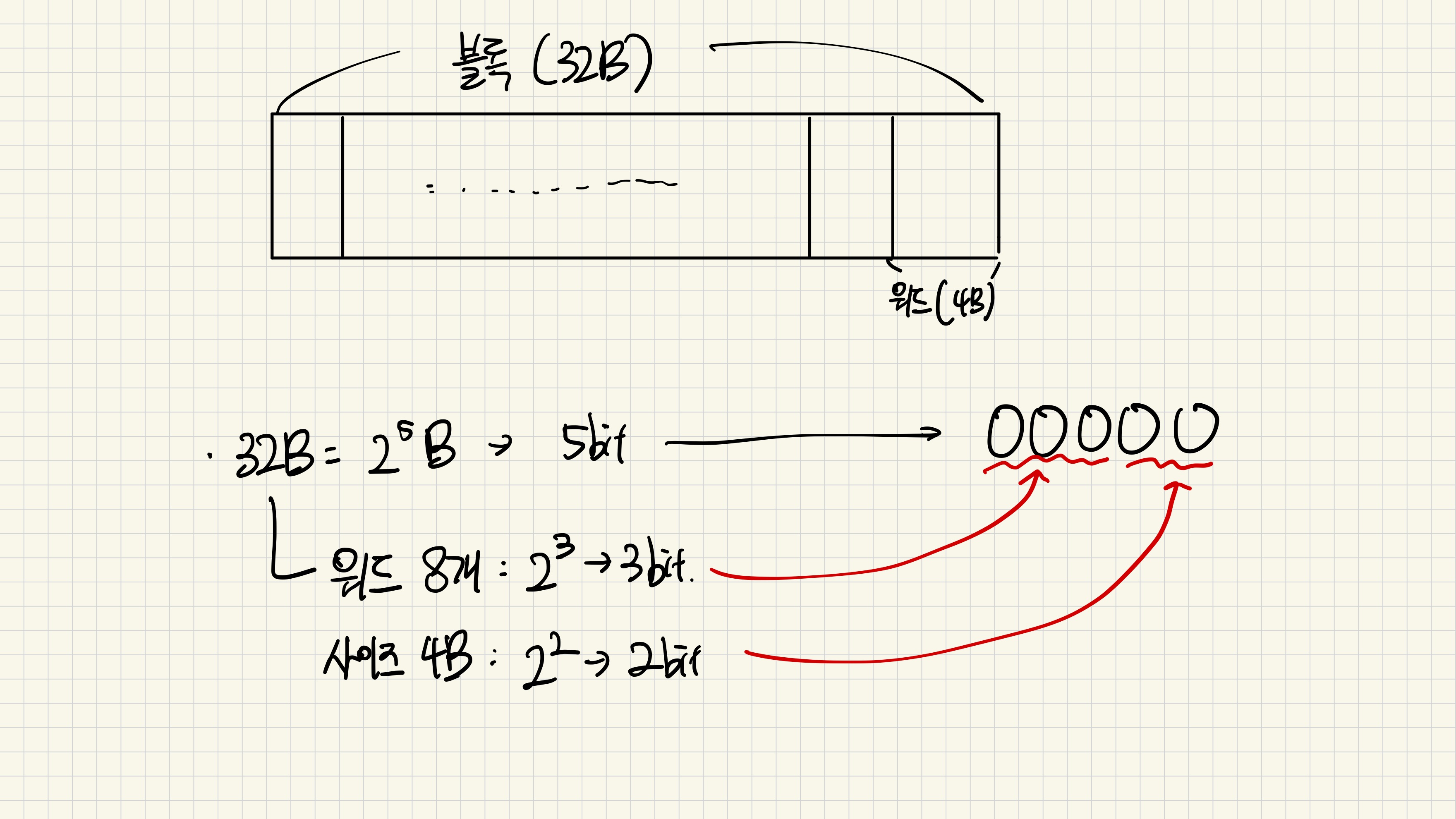
총 정리하면 아래와 같다.
- 상위 3비트 (비트 2, 3, 4): 이 비트들은 블록 내에서 워드의 위치를 선택하는 데 사용된다. 이 비트들은 0부터 7까지의 값을 가지며, 블록 내에서 각 워드의 시작 바이트를 지정한다.
- 하위 2비트 (비트 0, 1): 이 비트들은 워드 내에서 바이트의 위치를 지정하는 데 사용된다. 워드가 4바이트이므로, 이 2비트는 워드 내에서 0부터 3까지의 바이트 위치를 선택하는 데 필요하다.
💡 여전한 의문점 : 이 이미지는 무엇인가?
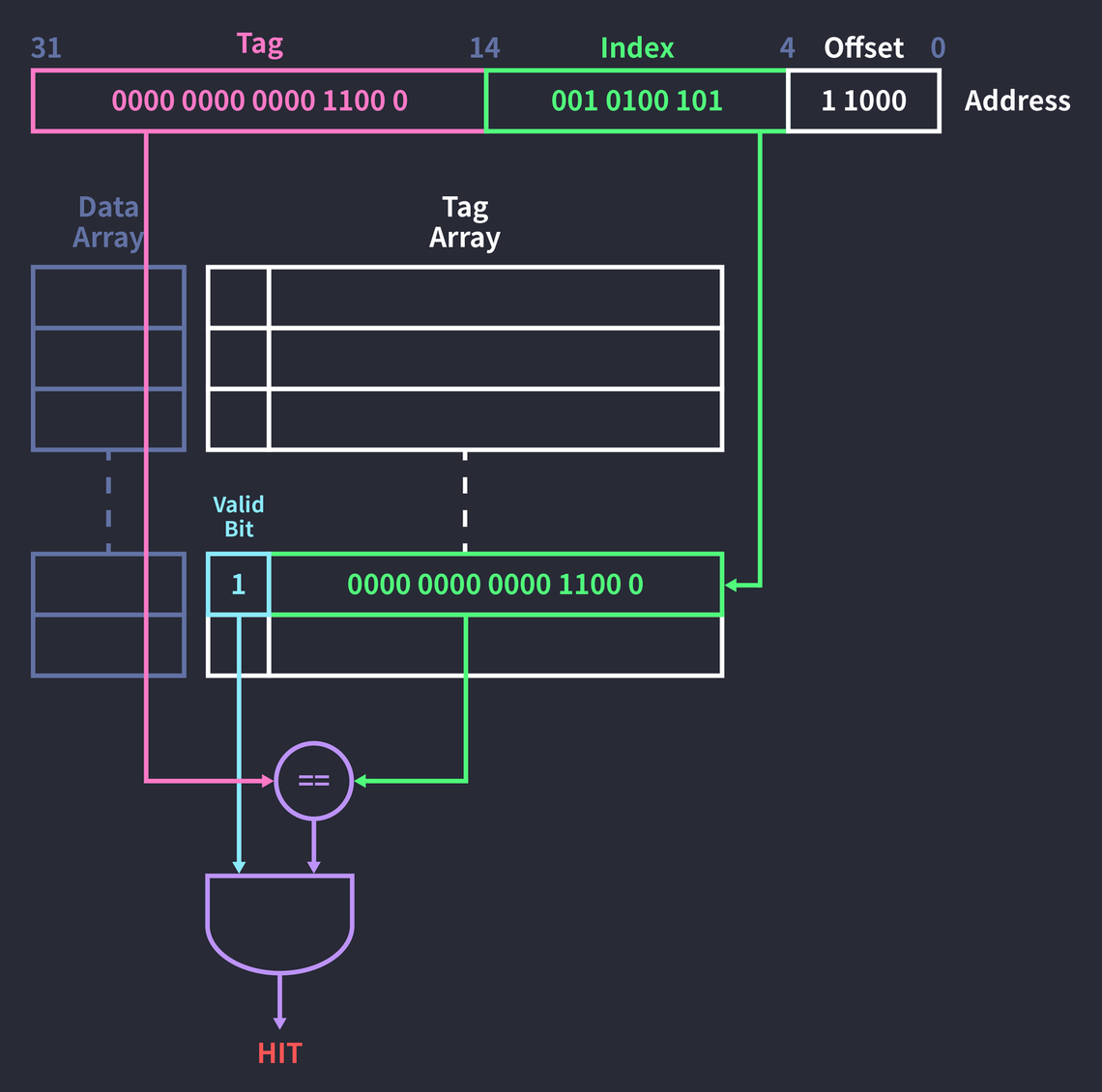
출처 : https://parksb.github.io/article/29.html
여기서는 태그 배열이 존재한다고 하셔서.. 어렵다 어려워. 내가 찾은 다른 참고자료들에는 이런 자료가 없어서 헷갈린다. 그래도 밑에 끄적여보였다.

🧷 참고 문헌
https://velog.io/@letskuku/컴퓨터구조-캐시-메모리
[컴퓨터구조] 캐시 메모리
캐시 메모리(cache memory)는 속도가 빠른 장치와 느린 장치 사이에서 속도 차에 따른 병목 현상을 줄이기 위한 범용 메모리이다. 대표적으로, 속도가 빠른 CPU 코어와 속도가 느린 메모리 사이에서
velog.io
https://developbear.tistory.com/75
[Chapter 5.2 컴퓨터 구조 및 설계] 직접 사상 캐시의 구조와 원리
본 정리는 CS422-컴퓨터 구조 및 설계 : 하드웨어/소프트웨어 인터페이스. David A. Patterson, 존 헤네시 책을 바탕으로 하고 있음을 미리 알립니다. 캐시의 구조 메모리 계층 구조에서는 상위 계층에
developbear.tistory.com
https://parksb.github.io/article/29.html
💵 캐시가 동작하는 아주 구체적인 원리: 하드웨어로 구현한 해시 테이블
기술의 발전으로 프로세서 속도는 빠르게 증가해온 반면, 메모리의 속도는 이를 따라가지 못했다. 프로세서가 아무리 빨라도 메모리의 처리 속도가 느리면 결과적으로 전체 시스템 속도는 느려
parksb.github.io
https://kimtaehyun98.tistory.com/48
Chapter 11. 캐시 메모리
# 본 내용은 한국항공대학교 길현영 교수님의 '컴퓨터 구조' 강의 및 컴퓨터 아키텍처(우종정, 한빛 아카데미)를 바탕으로 작성한 글입니다. 교재에는 메모리에 대한 챕터가 따로 있으나 강의에
kimtaehyun98.tistory.com
그리고 교수님 감사합니다..
'◎ CS > 컴퓨터구조' 카테고리의 다른 글
| 2. 2의 보수, 부동소수점 표현, 16진수, 비트 그룹 표현 (0) | 2024.03.12 |
|---|---|
| 1. 비트, 논리 연산, 비트 표현 (2) | 2024.03.11 |
자기계발 블로그

