![[OS] 가상 메모리 #1 (Virtual Memory)](https://img1.daumcdn.net/thumb/R750x0/?scode=mtistory2&fname=https%3A%2F%2Fblog.kakaocdn.net%2Fdn%2Fb94qVA%2FbtsHtc5cIHO%2Fn7xVX0HROFxvB7zKoRnQeK%2Fimg.png)

https://reo91004.vercel.app/os-2
[OS] 가상 메모리 (Virtual Memory)
가상 메모리의 모든 것
reo91004.vercel.app
더 잘 정리되어 있습니다.
🖥️ 시작하며
이전 포스팅에서 가상 메모리를 왜 쓰는지에 대해 알아봤으므로, 이번 포스팅에서는 가상 메모리를 구현하는 방법에는 무엇이 있는지 알아보려고 한다.
🔍 Paging

결국 가상 메모리를 쓰는 이유는, 물리 메모리를 효율적으로 쓰는 동시에 크고 연속적인 주소 공간을 보고 싶어서다. 페이징은 이런 프로그래머의 요구를 충족시켜 준다.
📌 Features
- 물리적 주소 공간이 비연속적일 수 있도록 허용한다.
- 물리적 메모리를
Frame이라는 고정된 크기의 블록으로 나눈다. - 논리적(가상) 메모리를
Page라는 동일한 크기의 블록으로 나눈다.Page는 보통 4KB의 크기를 가진다.
- 보통
Page와Frame은 같은 크기로 지정된다. (매칭을 편하게 하기 위함이지만 필수는 아니다.) - N 페이지 크기의 프로그램을 사용하려면, N개의 여유 프레임을 찾아 프로그램을 로드한다.
- OS는 빈 프레임을 추적하고 유지한다.
- 가상 주소(Page)를 실제 주소(Frame)로 변환할 수 있는
Page Table을 설정한다
32bit 운영체제에서 4GB 메모리를 장착했다고 가정하자.
**Frame의 개수** : 한 페이지의 크기는 4KB라 했고, 실제 메모리가 4GB가 존재하니 $4GB/4KB = 100만$. 즉 100만개의 Frame이 필요하다.
→ 중요! 이 Page Table은 사용하던 사용하지 않던 미리 만들어 둔다.
⚙️ 각 프로세스는 프로세스마다 가상의 주소 공간 페이지와 페이지 테이블을 가진다.

⚙️ 유저는 가상의 ‘크고 연속적인’ 주소 공간을 보고, 쓸 수 있게 된다.
또한 이 주소 공간은 프로세스마다 독립적이므로 보호도 적용된다.
⚙️ 가상-실제 맵핑은 오직 운영체제만 알아야 한다.
📌 주소 공간을 변환하는 방법
Virtual Address는 두 파트로 나뉘어져 있고, 아래와 같은 변환 과정을 거친다.
- <
Virtual Page Number (VPN)::offset>**VPN: Page Table의 인덱스****offset: 변위 차**
Page Table에서VPN이Page Frame Number (PFN)으로 변환된다.- 실제 주소는 <
PFN::offset>이 된다.
→ VPN 은 Page Table 을 거쳐 PFN 으로 변환된다.

💡 예시를 들어보자.
**Virtual Address: 32bit** (4GB)**Physical Address: 20bit** (1MB)- 이 컴퓨터의 물리 메모리는 1MB라는 의미
**Page Size: 4KB****Offset: 12bit**
여기서 아래와 같이 도출된다.

- 페이지 테이블의 크기는 $2^{20} * 8 = 1MB$이다.
- VPN이 20bit이므로 Page Table이 $2^{20}개$ 필요하다.
개괄적인 모식도는 아래와 같다.

🔍 Pag Table Entries (PTEs)

페이지 테이블 엔트리는 아래와 같이 구성되어 있다.
**Vaild bit (V)**: 가상의 주소가 사용되었는지 아닌지. 즉 데이터가 유효한지에 대한 여부다. Vaild bit가 0이라면 disk상에 데이터가 존재하는 것이므로Swapping해서 올라와야 한다.**Reference bit (R)**: 페이지에 엑세스되었는지. 읽기/쓰기 모두 표시한다.**Modify bit (B)**: 데이터가 Write 되었는지. 즉 데이터가 오염되었는지 체크한다.**Protection bits (Prot)**: Read/Write/Execute가 가능한지. 3개의 값을 알아야 하므로 2비트를 배정

📌 Advantges
- 물리적 메모리에 필요할 때마다 할당 가능하다.
- 비어 있는 Frame에 (보통 4KB씩) 할당한다.
- 외부 단편화가 없다.
- 4KB로 Fixed 되어있기 때문에
- 페이지 사이즈가 동일하므로, Disk로 내려보내거나 할 때 ‘그냥 지우면’ 된다.
- 주소 공간을 보호하기 좋다.
- 페이지를 공유해 프로세스끼리 데이터 공유가 용이하다.
📌 Disadvantages
- 내부 단편화가 존재한다.
- 당연히 페이지 안의 모든 공간을 쓰지 않을 수도 있다.
- Page Table은 메모리에 존재한다. 그러므로 메모리를 2번 읽고 쓰는 과정에서 오버헤드가 크다.
- Page Table을 만들어서 잡아둬야 하므로 공간 오버헤드가 발생한다.
- 보통 4MB크기의 Page Table이 생성된다. ($2^{20} * 4B$)
🔍 Demand Paging
- 프로그램이 요청할 때만 페이지를 생성함으로써 아래와 같은 이득이 생김
- I/O 감소
- 메모리 필요 감소
- 빠른 반응 속도
- 더 많은 프로그램을 돌릴 수 있음
- 운영체제가 Main Memory를
Cache처럼 사용하는 기법!- Disk에 있는 데이터들을 물리 메모리에 올려서 사용!
- → 마치 캐시처럼 작동.
- 만약 물리 메모리가 전부 찬다면,
**Swap수행** (eviection and load)
- 제거된
Pages들이 Disk로 이동할 때- Main Memory의
Page에서, Dirty 상태일 때만 다시 디스크에 쓰면 된다! - → 읽기만 했다면 데이터가 오염되지 않았으므로 업데이트 할 필요 없음
- Memory - Disk 간
Page이동은 OS에 의해 수행됨 - → 사용자 프로그램이 신경쓰지 않아도 됨
- Main Memory의
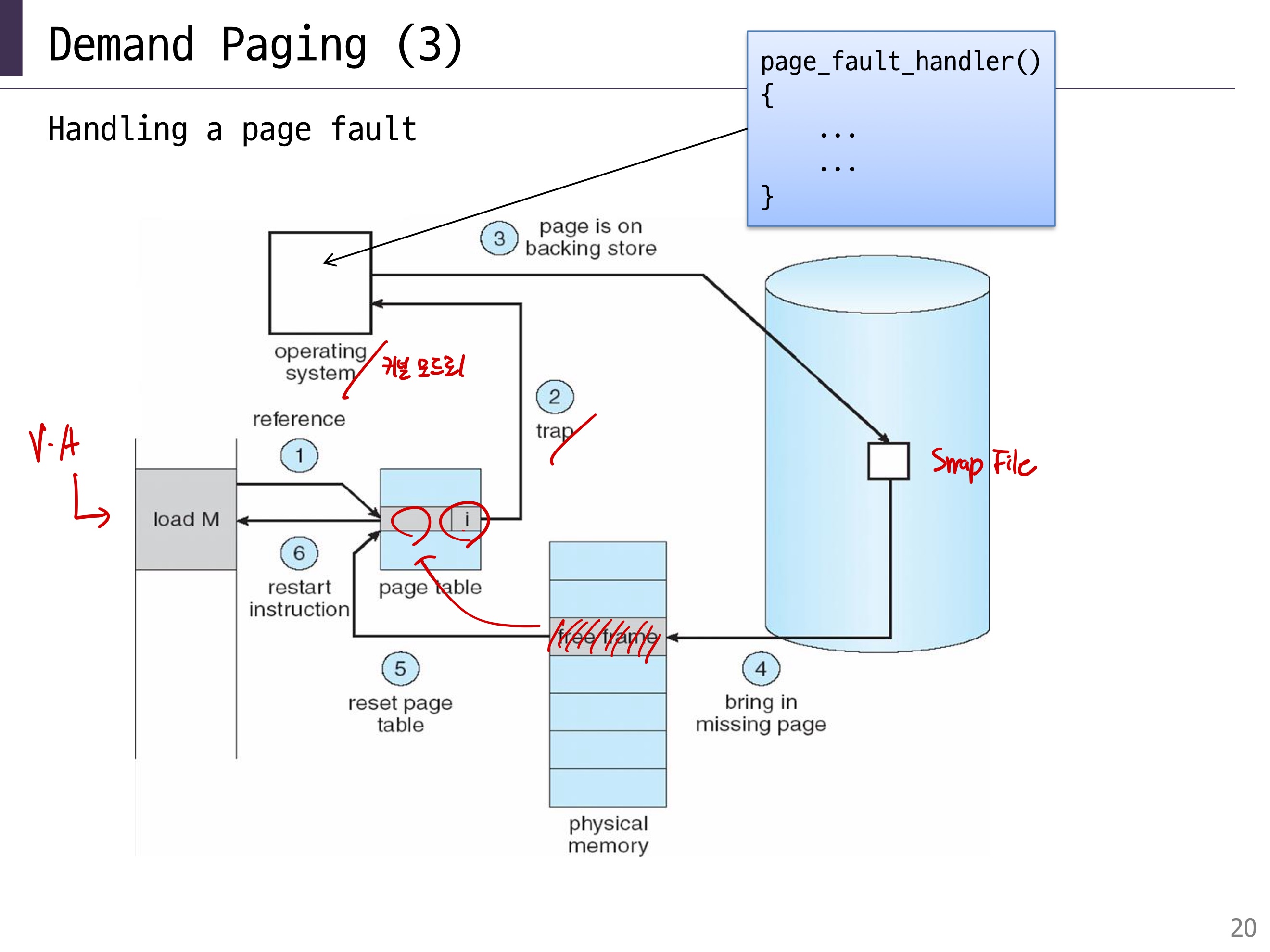
📌 Page Faults
- Page가 Disk로 내려갔을 때, OS는
**PTE (Page Table Entry)**의 Vaild 값을 0으로 변경 - 여기서 Page를 참조하려고 할 때 예외가 발생 → Page Faults!
⚙️ Page Faults가 일어나면 OS가 Page Fault Handler 실행
PTE에 저장된 위치 정보를 토대로 Swap 파일에서 페이지를 찾고, 이를 물리 메모리의 빈 프레임에 로드함
💡궁금증 : 그렇다면 PTE에 위치 정보가 어떻게 저장될까?
- Valid Bit 사용: PTE의 Valid Bit가 0이면, 해당 페이지가 스왑 파일에 있음을 나타낸다.
- 이때 PFN 필드는 실제 물리 프레임 번호가 아니라 스왑 파일의 위치를 나타내는 데 사용됨.
📎 예시로 설명
- PTE의 구조 (페이지가 물리 메모리에)
- Valid Bit: 1
- Reference Bit: 1 (최근에 참조됨)
- Modify Bit: 0 (수정되지 않음)
- Protection Bits: 011 (읽기, 쓰기 권한)
- PFN: 0x1F4 (물리 메모리의 프레임 번호)
- PTE의 구조 (페이지가 스왑 파일에)
- Valid Bit: 0
- Reference Bit: 1 (최근에 참조됨)
- Modify Bit: 1 (수정됨)
- Protection Bits: 011 (읽기, 쓰기 권한)
- PFN: 0x2A3 (스왑 파일의 블록 번호)
그런데, 물리 메모리에 빈 프레임이 없다면?
- 누구를 물리 메모리 프레임에서 뺄 것인지에 대한 알고리즘이 중요해 진다.
- 하지만, 보통 OS가 빈 공간을 확보, 유지 중이다.
📌 위와 같은 작업들이 어떻게 가능한가?
1️⃣ 지역성 (Locality)
- 시간적 지연성 : 최근에 참조된 위치는 곧 다시 참조됨
- 공간적 지연성 : 최근 참조된 위치 근처는 곧 다시 참조됨
2️⃣ Locality는 Page Faults가 그다지 일어나지 않는다는 의미도 내포
- 일단 호출하면 여러 번 사용되고, 평균적으로 호출된 것을 호출함
- 허나 이런 특성은 여러 가지에 의존됨
- 사용자 프로그램의 지역성 정도
- 페이지 교체 정책
- 물리 메모리의 크기
- 사용자 프로그램의 참조 패턴 및 메모리 사용량
📌 왜 이게 “Demand” Paging인가?

페이지 테이블의 생성 과정을 다시 보자.
- 프로세스가 처음 시작되면,
**PTE**의**Vaild bit**가 모두**false**인 새로운 페이지 테이블을 만듦- 모든 페이지들은 비어 있다!
- 아직 물리적 메모리에 매핑된 페이지가 없음. 즉, 메모리에 로드되지 않고 아직 디스크에 존재
- 프로세스가 실행을 시작하면
- 처음에는 다 비어있기 때문에
**Page Fault**발생 **Faults**는 필요한 코드나 데이터가 메모리에 들어가면 멈춤- 필요한 데이터만 로드하면 됨
- 처음에는 다 비어있기 때문에
🔍 Segmentation
- 사용자는 메모리를 다양한 사이즈의 세그먼트 모음으로 보게 됨
- 이 세그먼트 모음에 순서는 없음
- 가상 주소는
**<Segment # :: Offset>** 으로 나타남
- 서로 다른 세그먼트가 독립적으로 크기를 변형할 수 있음
- 가변 파티션의 자연스러운 확장이 가능함
- 가변 파티션 : 한 프로세스가 하나의 세그먼트를 가짐
- Segmentation : 한 프로세스가 많은 세그먼트를 가짐
⚙️ 가변 크기 파티션 VS Segmentation
1️⃣ 가변 크기 파티션 (Variable-sized Partitions)
- 가변 크기 파티션은 프로세스가 필요로 하는 메모리 크기에 맞춰 동적으로 할당되는 메모리 블록을 의미
- 1 segment / process는 각 프로세스가 하나의 큰 메모리 블록(세그먼트)을 할당받는다는 것
- 외부 단편화 문제가 생길 수 있음
2️⃣ 세그멘테이션 (Segmentation)
- 세그멘테이션은 프로세스가 여러 개의 세그먼트로 구성된다는 개념
각 세그먼트는 논리적으로 관련된 데이터 단위(예: 코드, 스택, 힙 등)를 포함 - many segments / process는 각 프로세스가 여러 개의 세그먼트를 가질 수 있다는 뜻

📌 Hardware Support
**limit 레지스터와 base 레지스터를 통해 물리 메모리 위치를 찾음**

📌 Advantages
- 세그먼트 데이터 구조를 수정하기 쉽다.
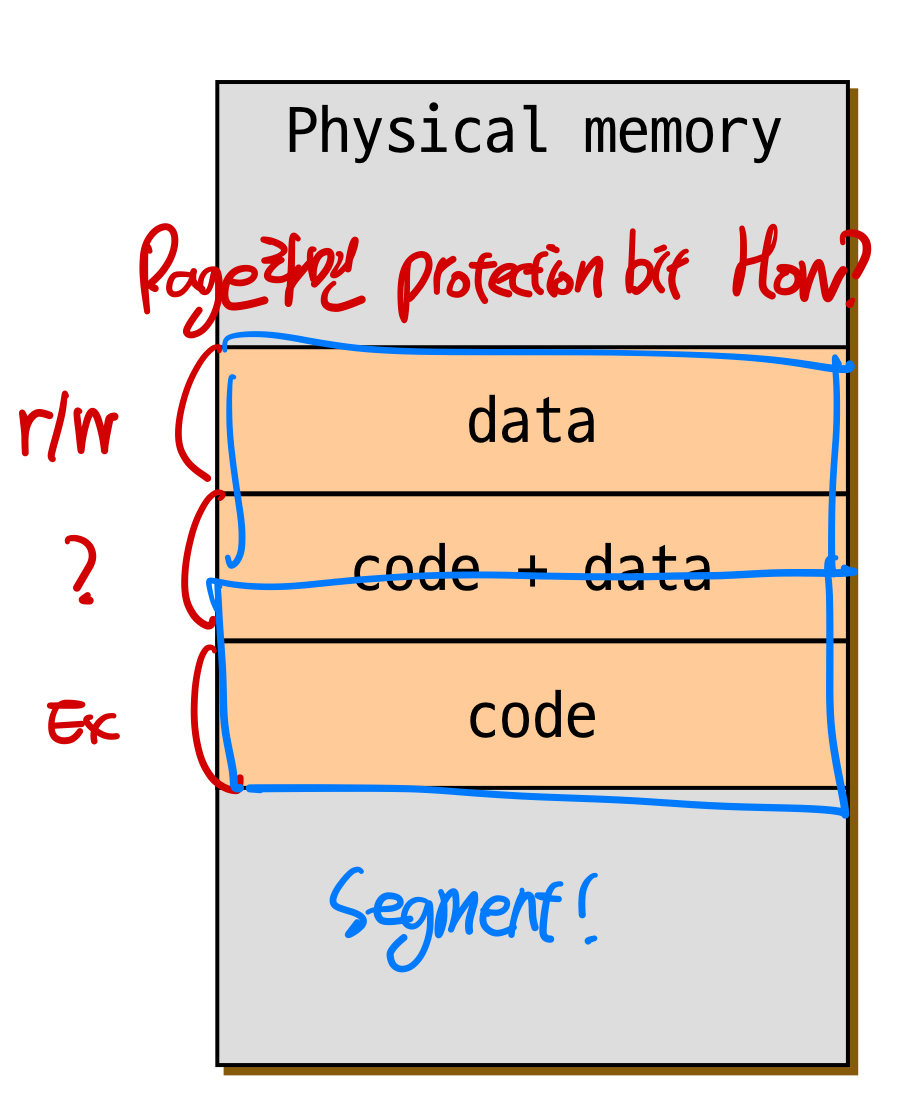
**limit레지스터만 변경하면 되기 때문!** - 세그먼트를 보호하기 쉽다.
Page방식이면 아래와 같은 사진에서Protection bit에 관한 권한 처리를 별도로 하기 힘들지만, 세그먼트라면 쉽게 가능
- 세그먼트를 다른 프로세스와 공유하기 용이하다.
**base**,**limit**레지스터를 공유하면 되기 때문!- 보통
Code,Data섹션을 공유한다.
- 보통
📌 Disadvantages
- 주소 공간이 연속적이지 않으므로 포인터 사용이 어렵다.
- 세그먼트 간에 포인터를 공유하려면, 포인터가 가리키는 세그먼트 번호가 같아야 함
- 예를 들어, 프로세스 A의 세그먼트 2에 있는 데이터를 프로세스 B도 접근하려면 프로세스 B에서도 같은 세그먼트 번호 2를 사용해야 함
- 만약 세그먼트 번호가 다르면, 직접 주소 참조가 불가능해지고, 대신 간접 주소 방식(indirect addressing)을 사용하게 됨
- → 이는 간접 주소 테이블을 통해 실제 세그먼트를 찾아가는 방식으로, 성능 저하와 복잡성을 유발
- 세그먼트 간에 포인터를 공유하려면, 포인터가 가리키는 세그먼트 번호가 같아야 함
- 세그먼트 테이블이 커짐
- 외부 단편화 존재

🔍 Paging vs Segmentation
| Paging | Segmentation | |
|---|---|---|
| 블럭 사이즈 | Fixed (4KB에서 64KB, OS마다 마다 상이) | Variable (코드의 영역) |
| 연속적인 가상 공간 | 1개 (4GB 1개) | 많음 (포인터 사용 시 문제) |
| 메모리 주소 정의 | Page number + offset | Segment + offset |
| 교체 용이성 | Easy (모두 같은 사이즈) | Difficult (영역마다 사이즈 다름) |
| 디스크 트래픽 (디스크 옮기는) | 효율적 (모두 같은 사이즈) | 비효율적 (작거나 큰 사이즈) |
| 단편화 | 내부 단편화 | 외부 단편화 |
| 프로그래머에게 친숙한가? | Yes (Linear한 4GB 영역 1개) | No |
| 총 주소 공간이 물러직 메모리의 크기를 초과할 수 있나? | Yes | Yes |
| 코드와 데이터를 구분해 별도 보호할 수 있나? | No | Yes |
| 가변 테이블을 쉽게 수용할 수 있나? | No | Yes |
| 코드 공유가 쉽나? | No | Yes |
| 왜 이 기술이 발명되었나? | 크고 선형 구조인 주소 공간을 위해 | 논리적으로 독립적인 주소 공간을 위해 (공유와 보호가 쉬움) |
⚙️ 보통 세그먼트 기법과 페이징 기법을 섞어서 사용함! (Segment 내부를 Page로 나누는 식)
📌 Combine Segmentation with Paging
- 논리적으로 비슷한 유닛들을 Segment로 관리
- 코드, 데이터, 힙, 스택 등
- 세그먼트의 크기는 다양하지만 보통 큼 (여러 페이지)
- 페이지를 사용해 세그먼트를 고정된 크기의 청크로 분할
- 물리 메모리 내에서 세그먼트를 더 쉽게 관리 가능
- 세그먼트가
Pageable하다 : Demand Paging처럼 일부는 Memory에, 일부는 Disk에 적재 - → 세그먼트 전체를 Swap할 필요 없이, 부분부분 페이지를 스왑하면 된다!
- 외부 단편화 없음!

자기계발 블로그